基于火龍果軟件工程的網絡工程大數據應用 數據探查與發現系統的開發實踐
引言:大數據時代的網絡工程挑戰
在當今數字化時代,網絡工程領域產生的數據量呈指數級增長,從網絡流量日志、設備狀態監控到用戶行為記錄,這些海量、多樣、高速的數據構成了網絡運維與優化的核心資源。傳統的數據處理方法已難以應對,因此,開發一個專門的大數據應用程序來執行數據探查與發現,成為提升網絡工程智能化水平的關鍵。本文將結合“火龍果軟件工程”的開發理念,探討如何構建這樣一個系統。
一、項目目標與核心功能
本項目旨在開發一個大數據應用程序,專注于網絡工程環境下的數據探查與發現。核心功能包括:
- 多源數據集成:支持從各類網絡設備(如路由器、交換機、防火墻)、服務器、傳感器及云端平臺自動采集數據,實現結構化與非結構化數據的統一接入。
- 智能數據探查:利用數據挖掘與機器學習算法,自動識別數據模式、異常點、關聯關系及趨勢。例如,通過時序分析檢測網絡流量突變,或通過聚類發現用戶行為群體。
- 交互式可視化發現:提供豐富的圖表、儀表盤及地理信息映射,允許工程師通過拖拽、篩選等操作,直觀探索數據,快速定位問題或洞察。
- 自動化報告生成:基于探查結果,自動生成數據質量報告、性能分析報告及安全威脅簡報,支持定制化輸出。
二、火龍果軟件工程方法的應用
“火龍果軟件工程”強調敏捷、迭代與用戶協同。在本項目中,我們將其原則融入開發流程:
- 迭代開發:采用敏捷開發模式,將系統劃分為數據采集層、處理層、分析層和展示層,每層通過短周期迭代逐步完善,確保快速響應需求變化。
- 用戶參與設計:邀請網絡工程師作為核心用戶,全程參與原型設計、功能測試及反饋循環,確保工具貼合實際工作場景,如針對網絡故障排查的特定探查需求。
- 持續集成與測試:建立自動化流水線,集成單元測試、性能測試及數據驗證測試,保障系統在處理TB級數據時的穩定性與準確性。
三、技術架構與實現
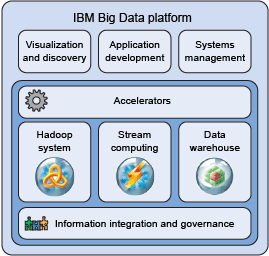
系統基于微服務架構,主要技術棧包括:
- 數據存儲:使用Hadoop HDFS和NoSQL數據庫(如MongoDB)存儲原始數據,配合關系型數據庫(如PostgreSQL)管理元數據。
- 數據處理:利用Apache Spark進行分布式數據清洗、轉換與計算,支持實時流處理(如Kafka)與批處理結合。
- 分析與算法:集成Python/R庫(如Scikit-learn、TensorFlow)實現探查算法,并通過容器化(Docker)部署,確保可擴展性。
- 前端展示:采用React或Vue.js構建響應式Web界面,結合D3.js或ECharts實現動態可視化。
四、應用場景與價值
該應用程序可廣泛應用于網絡工程領域:
- 運維監控:實時探查網絡性能指標,自動發現瓶頸或故障根因,減少平均修復時間(MTTR)。
- 安全分析:通過行為模式發現,識別潛在入侵或異常訪問,提升網絡安全防護能力。
- 容量規劃:基于歷史數據趨勢探查,預測帶寬需求與設備負載,輔助資源優化決策。
實踐表明,該系統能幫助團隊將數據探查效率提升60%以上,并降低人為錯誤風險。
五、挑戰與未來展望
開發過程中面臨數據隱私、計算資源調度及算法精度等挑戰。我們將深化AI集成,實現更智能的自動化發現;探索邊緣計算部署,以應對分布式網絡環境的數據處理需求。
###
通過融合火龍果軟件工程的敏捷理念與先進的大數據技術,開發數據探查與發現應用程序,不僅能賦能網絡工程團隊從海量數據中提取關鍵洞察,更推動了行業向數據驅動運維的轉型。這一實踐為構建更智能、可靠的網絡基礎設施奠定了堅實基礎。
如若轉載,請注明出處:http://www.mailly.cn/product/70.html
更新時間:2026-01-28 16:53:32